Khi bắt đầu triển khai PostgreSQL trên Kubernetes, nhiều người thường tập trung vào StatefulSet, PVC hay backup strategy, nhưng chỉ đến lúc nghĩ về sự cố thực tế mới thấy một câu hỏi khó hơn nhiều: nếu primary node bị crash thì điều gì sẽ xảy ra tiếp theo? Ai sẽ quyết định node nào được lên làm primary mới, và làm sao để quá trình đó diễn ra an toàn mà không gây split-brain? Đó là lúc Patroni trở thành một thành phần rất đáng để hiểu kỹ, không chỉ ở mức “biết dùng”, mà còn ở mức “biết vì sao nó hoạt động được”.
Trong bài viết này, mình sẽ cùng bạn đi qua cách Patroni triển khai high availability cho PostgreSQL trong Kubernetes, theo hướng dễ hình dung và bám sát cơ chế thực tế bên trong. Mục tiêu không phải chỉ để cấu hình Patroni chạy được, mà là để bạn hiểu rõ các khái niệm cốt lõi như leader lock, health check loop, leader race và failsafe mode.
Vấn đề
Hãy tưởng tượng: 2 giờ sáng, primary node của PostgreSQL cluster đột ngột crash. Các ứng dụng bắt đầu báo lỗi kết nối. Alert dồn dập kéo đến. Câu hỏi đặt ra: ai hoặc cái gì sẽ bầu chọn primary node mới trước khi người dùng kịp nhận ra có sự cố?
PostgreSQL không có cơ chế HA tích hợp sẵn. Nếu primary node crash, toàn bộ cluster trở thành read-only hoặc ngừng hoạt động hoàn toàn cho đến khi DBA can thiệp thủ công. Trên Kubernetes, vấn đề này càng phức tạp hơn: pod có thể bị reschedule bất kỳ lúc nào, IP thay đổi, và không phải lúc nào cũng có DBA phản ứng kịp trong vài giây đầu tiên.
Đây chính là bài toán mà Patroni được tạo ra để giải quyết. Patroni là một high-availability (HA) solution cho PostgreSQL trên nhiều môi trường runtime khác nhau, sử dụng cơ chế failover tự động để đảm bảo cluster PostgreSQL hoạt động kể cả khi primary node gặp sự cố. Bài viết này giải thích cơ chế hoạt động bên trong của Patroni trong Kubernetes: từ cách health check định kỳ, cơ chế leader lock, đến cách phòng tránh race condition.
Tóm tắt
Sau khi đọc bài này, bạn sẽ hiểu:
- Cách Patroni tổ chức vòng lặp health check để đảm bảo cluster hoạt động bình thường.
- Cơ chế Leader Race: điều kiện để một Replica được promote, và thứ tự bầu chọn.
- Cách Patroni phòng tránh split-brain với resourceVersion của Kubernetes.
- Failsafe Mode hoạt động như thế nào và hạn chế của nó khi DCS bị lỗi.
- Điểm mạnh, hạn chế, và khi nào nên (hoặc không nên) chọn Patroni.
Giải thích thuật ngữ
PostgreSQL cluster: Một nhóm node được triển khai theo kiến trúc 1 Primary — N Replica.
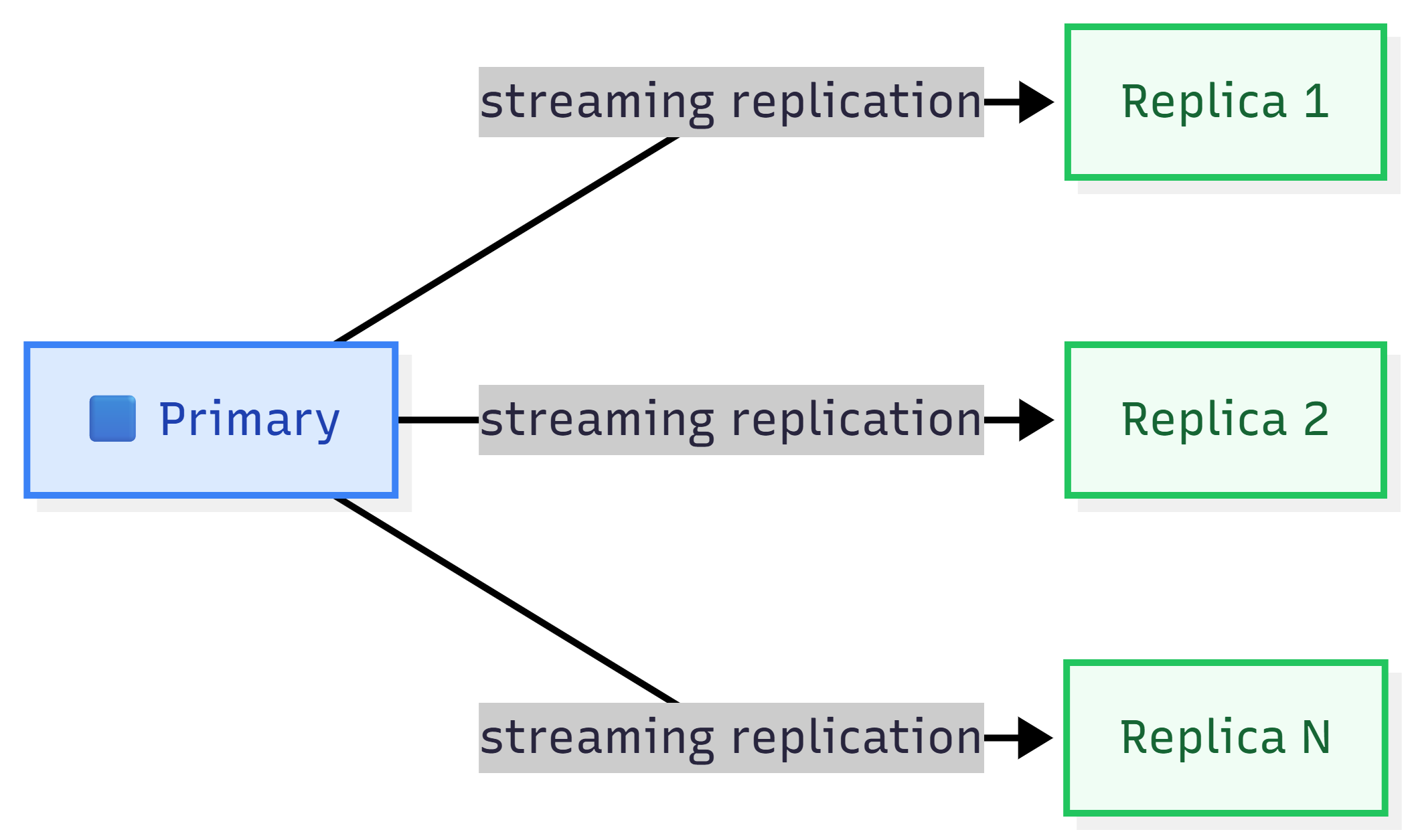
Kiến trúc cụm PostgreSQL 1 Master – N Replica
Race condition: Tình trạng xảy ra khi nhiều tiến trình cùng cố gắng thay đổi cùng một tài nguyên chia sẻ, dẫn đến kết quả không mong muốn.
resourceVersion: Kubernetes sử dụng resourceVersion để triển khai cơ chế optimistic concurrency. Khi cập nhật một resource, Kubernetes sẽ kiểm tra xem resourceVersion trong request có khớp với resourceVersion hiện có hay không.
- Nếu trùng khớp: cập nhật được chấp nhận và resourceVersion được cập nhật sang giá trị mới.
- Nếu không trùng khớp: Kubernetes từ chối cập nhật và trả về mã lỗi HTTP 409.
Ví dụ: Giả sử đang có một tài nguyên Service với resourceVersion: 308. Ta cập nhật Service đó nhưng gửi kèm một resourceVersion khác 308 (có thể do ai đó đã cập nhật trước đó). Kết quả: request nhận về HTTP 409, cập nhật thất bại.
Kiến trúc và mô hình hoạt động của Patroni
1. Mô hình tổng quan
Patroni sử dụng một DCS (Distributed Configuration Store) làm source of truth để lưu trữ metadata của cluster. Patroni hỗ trợ nhiều loại DCS khác nhau: etcd, Consul, ZooKeeper, và Kubernetes ConfigMap/Endpoint.
Patroni được deploy tại mỗi node PostgreSQL hay mỗi node có một Patroni instance riêng. Cluster Patroni có topology tương ứng với cluster PostgreSQL: một Primary và N Replica. Patroni Primary nắm giữ một leader lock lưu trữ tại DCS; các Patroni Replica theo dõi lock này.
Vai trò của mỗi Patroni instance được xác định thông qua DCS và quyết định trực tiếp vai trò của PostgreSQL instance tương ứng: Patroni nào giữ leader lock thì PostgreSQL instance đó được promote lên Primary; các Patroni còn lại chạy ở vai trò Replica thì PostgreSQL instance đó là Replica.
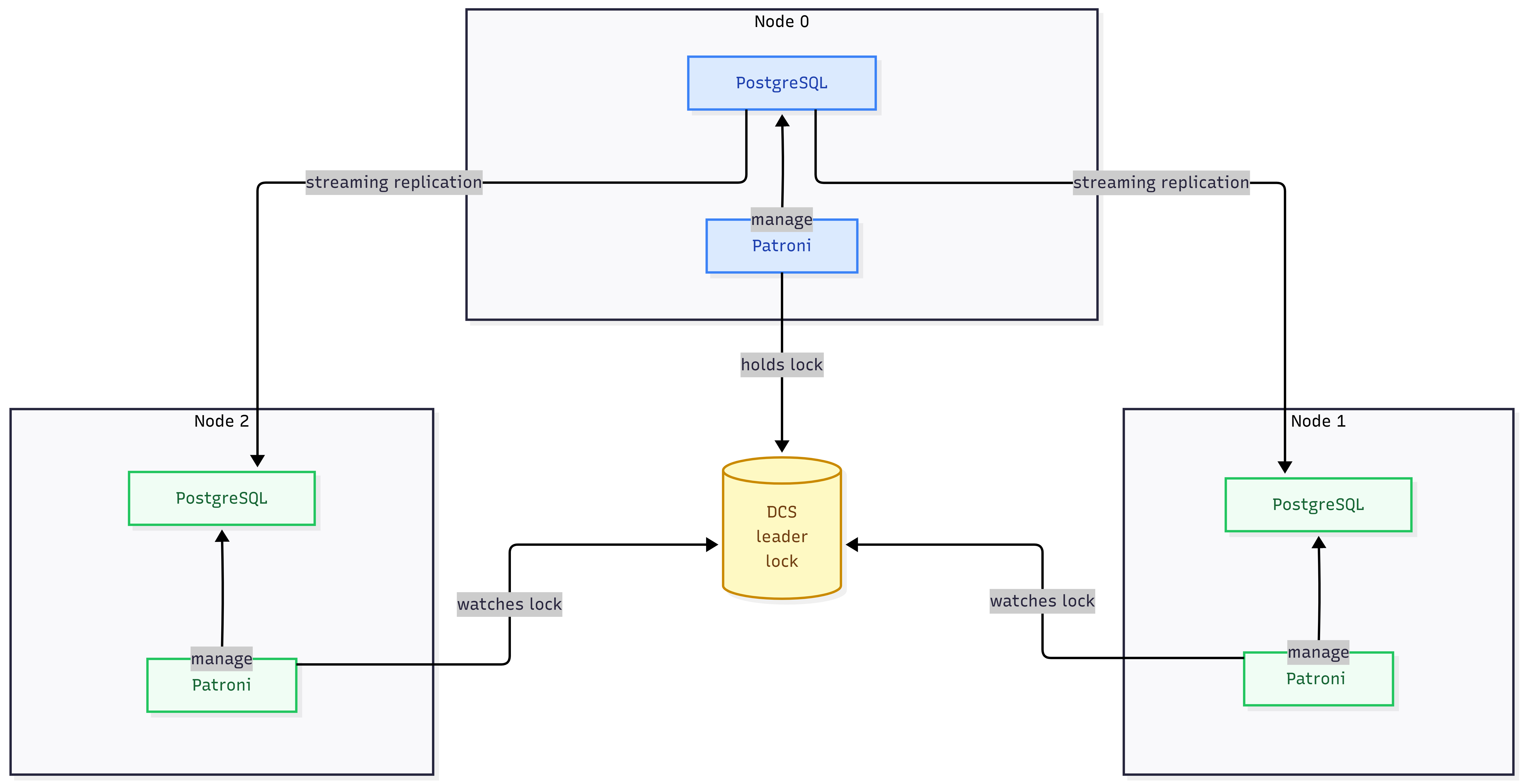
Mô hình triển khai của Patroni
2. Vòng lặp Health Check
Patroni hỗ trợ hai cơ chế lưu trữ leader lock trên Kubernetes: Endpoints và ConfigMaps. Bài viết này sẽ tập trung vào cách Kubernetes Endpoint đóng vai trò làm DCS. Khi sử dụng Kubernetes Endpoints làm DCS, leader lock được lưu như sau:
$ kubectl get ep postgres-cluster -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
leader: postgres-cluster-0
renewTime: "2026-05-10T09:03:36.094563+00:00"
ttl: "30"
name: postgres-cluster
resourceVersion: "49818310"
...
Leader lock thực chất là một Endpoints resource trên Kubernetes, trong đó annotation renewTime ghi lại thời điểm Patroni Primary cập nhật lock lần cuối. Leader lock đi kèm với TTL (time to live).
Patroni kiểm tra trạng thái cluster theo chu kỳ (mặc định mỗi 10 giây, cấu hình bởi tham số loop_wait). Trong mỗi chu kỳ, Patroni thực hiện tuần tự:
- Lấy thông tin từ DCS.
- Kiểm tra trạng thái leader lock:
- Nếu lock còn hiệu lực: Primary cập nhật lock, các Replica không thực hiện thao tác nào với lock.
- Nếu lock hết hạn (hoặc không tồn tại): các Replica đồng loạt tranh giành lock mới – đây là leader race.
Ví dụ: Lock được renew lúc 11:30:00 với TTL 30 giây. Nếu đến 11:30:30 lock vẫn chưa được renew, các Replica bắt đầu một leader race.
3. Failover tự động
Khi leader lock hết hạn:
- Mỗi Patroni Replica kiểm tra xem bản thân có đủ điều kiện trở thành leader mới hay không, dựa trên ba điều kiện:
- Lag: Độ trễ replication không vượt quá maximum_lag_on_failover.
- Timeline: Node đang ở WAL timeline tương thích với cluster.
- Quorum (nếu bật synchronous mode): Node phải nằm trong danh sách synchronous standby, tức là đã nhận và ghi đủ WAL từ Primary trước khi Primary crash.
- Patroni Replica nào đầu tiên giành được lock sẽ được promote lên làm Patroni Primary. Khi này, Patroni gọi pg_promote() để promote PostgreSQL instance tương ứng. Các node còn lại nhận diện leader mới và chuyển sang theo dõi lock của node đó.
Song song với đó, nếu Patroni Primary cũ phục hồi sau sự cố và phát hiện đã có leader mới, Patroni sẽ tự động thực hiện quá trình demote: dừng PostgreSQL, chạy pg_rewind để đồng bộ WAL timeline với Primary mới (nếu được bật), rồi khởi động lại ở chế độ standby.
Patroni đảm bảo không có leader race giữa các Patroni Replica như thế nào?
Patroni sử dụng cơ chế resourceVersion của Kubernetes để đảm bảo không xảy ra race condition trong quá trình bầu chọn leader. Mỗi node gửi request cập nhật lock kèm theo resourceVersion hiện tại của Endpoint:
- Nếu resourceVersion khớp: request thành công, node trở thành leader mới.
- Nếu resourceVersion không khớp: Kubernetes trả về HTTP 409 (StatusConflict), node không thể trở thành leader.
Trường hợp 1 – Nhiều node cùng tranh lock: resourceVersion hiện tại là 100. Hai Replica đồng thời gửi request cập nhật Endpoint với resourceVersion = 100. Request đến trước thành công, node đó được promote lên Primary. Các request còn lại nhận HTTP 409 do resourceVersion đã thay đổi.
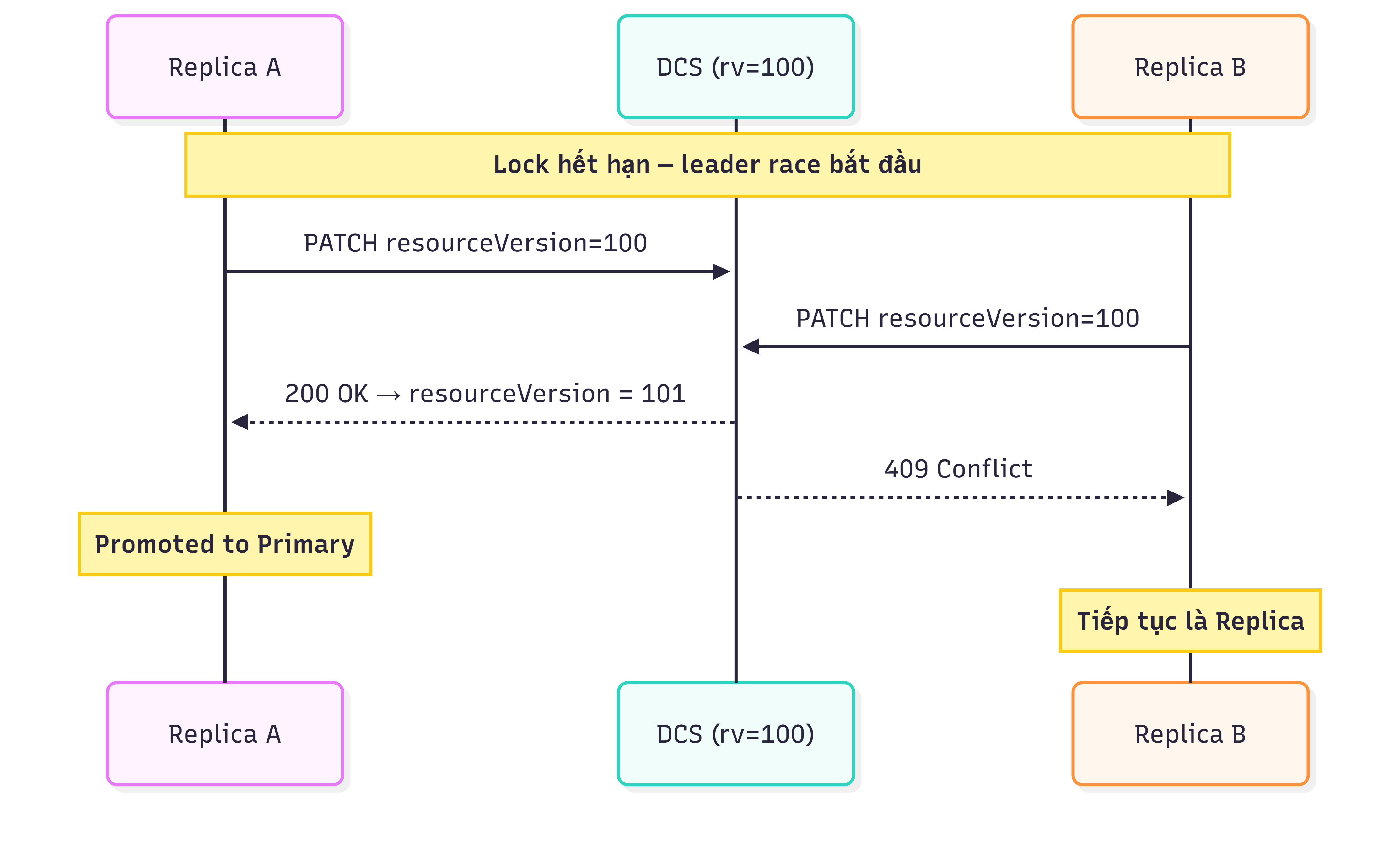
Sequence diagram của trường hợp 1
Trường hợp 2 – Node bị chậm: resourceVersion ban đầu là 100. Node A cập nhật thành công và trở thành leader, resourceVersion tăng lên 101. Node B bị chậm; khi thực hiện thao tác, nó đọc trạng thái mới nhất với resourceVersion = 101, nhận ra đã có leader hợp lệ và tiếp tục hoạt động như một Replica.
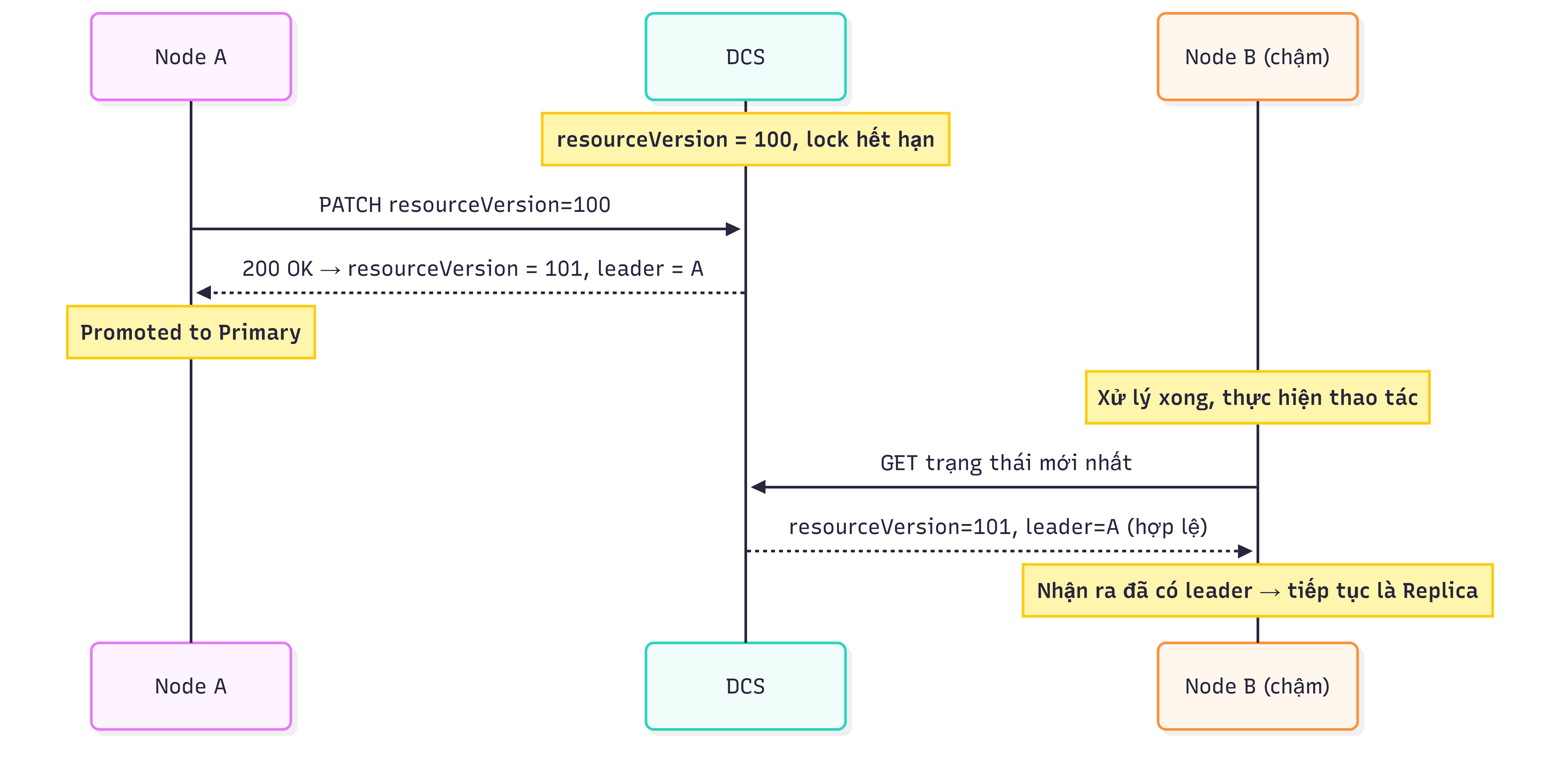
Sequence diagram của trường hợp 2
Trường hợp 3 – Request renewal bị trễ: Nếu request renewal của Primary bị trễ đủ lâu để lock hết hạn, leader race được kích hoạt và một node mới được bầu, resourceVersion thay đổi. Khi request cũ của Primary cuối cùng đến nơi, Kubernetes từ chối với HTTP 409 do resourceVersion không còn khớp. Primary cũ nhận ra mình đã mất lock và tự chuyển về vai trò Replica.
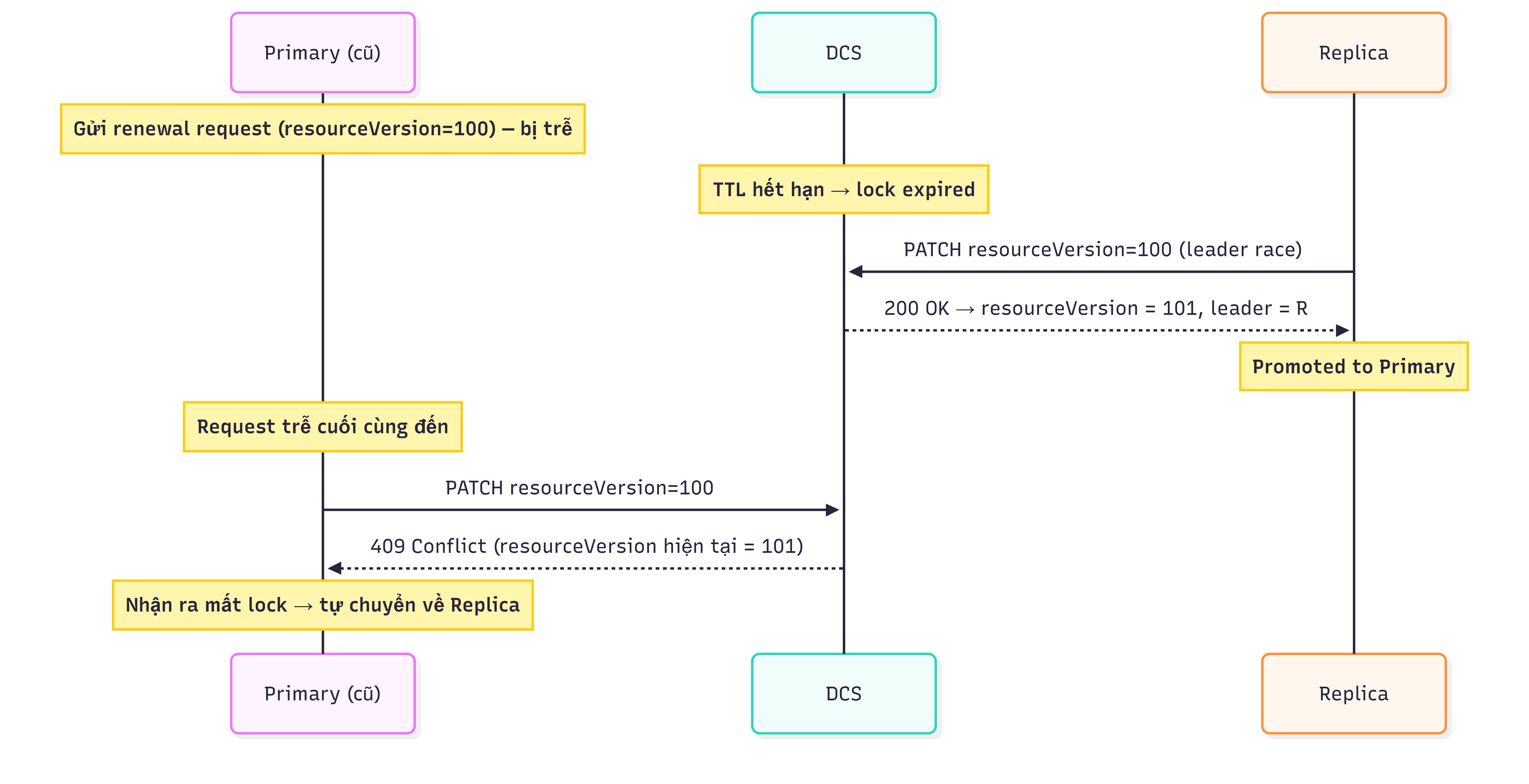
Sequence diagram của trường hợp 3
4. Chế độ Failsafe
Chế độ Failsafe là lớp bảo vệ thứ hai khi DCS không hoạt động. Khi được bật, Primary có thể tiếp tục giữ vai trò của mình nếu vẫn kết nối được với tất cả các node khác trong cluster thông qua REST API của Patroni.
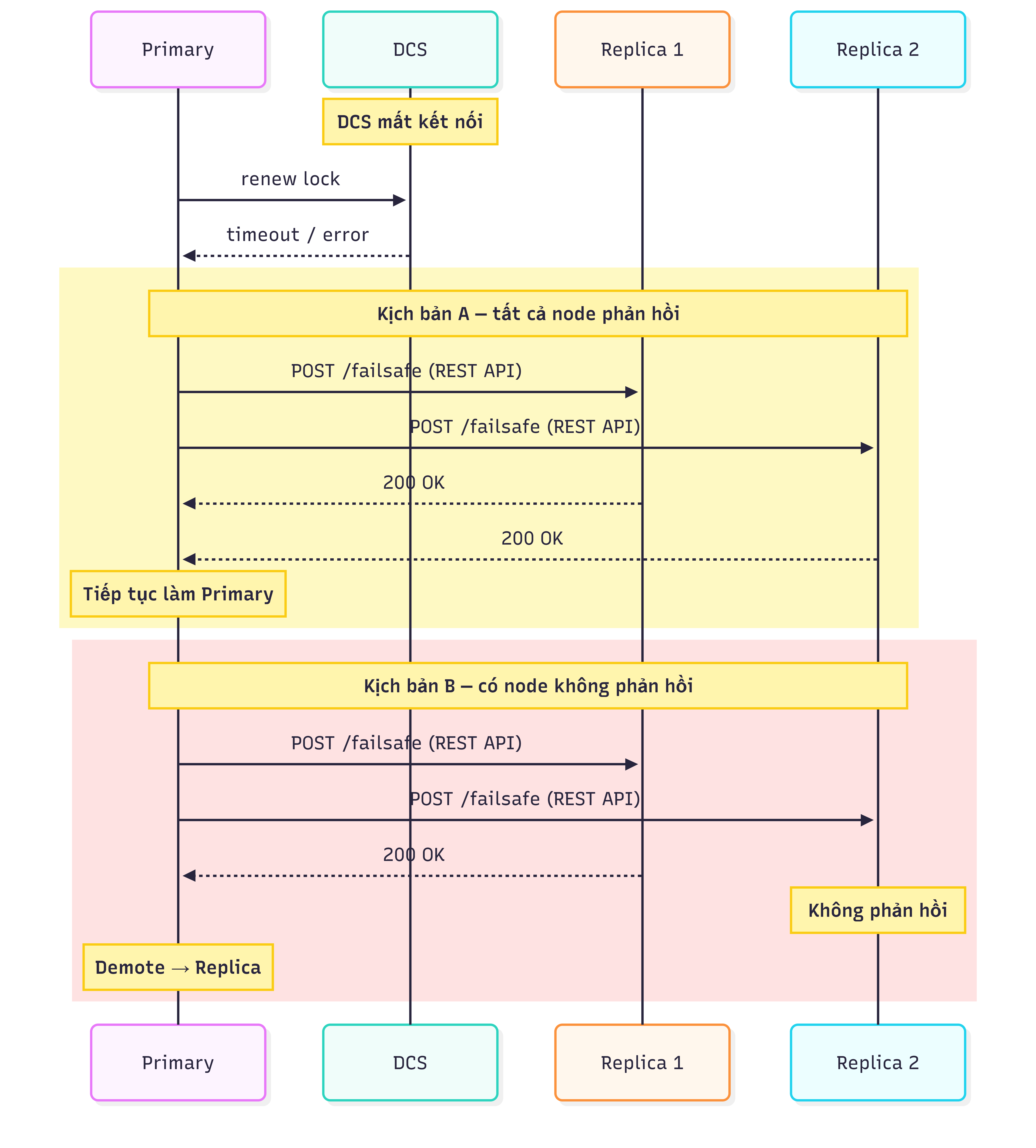
Sequence diagram mô tả cách hoạt động của failsafe mode trong Patroni
Tuy nhiên, trong trạng thái này, failover không còn khả dụng. Nếu Primary gặp sự cố khi Failsafe đang hoạt động, không có Replica nào được bầu lên thay thế. Toàn bộ cluster trở thành read-only.
Những điểm cần cân nhắc khi triển khai PostgreSQL high availability với Patroni trên Kubernetes
Điểm mạnh:
- Tích hợp native với Kubernetes, dùng Endpoints làm DCS mà không cần etcd riêng.
- Bầu chọn leader hoàn toàn tự động.
- Hỗ trợ đa dạng tùy chọn HA: Failsafe Mode, synchronous replication, custom bootstrap hooks.
- Cộng đồng lớn, tài liệu phong phú.
- Hỗ trợ nhiều DCS backend: etcd, Consul, ZooKeeper, Kubernetes Endpoints.
Hạn chế:
- Phụ thuộc vào DCS: nếu DCS bị lỗi, cluster có thể rơi vào trạng thái read-only – trừ khi bật Failsafe Mode.
- Độ phức tạp vận hành cao hơn so với managed services (RDS, CloudSQL, AlloyDB).
- Cần hiểu rõ các tham số ttl, loop_wait, maximum_lag_on_failover để cấu hình phù hợp với từng workload.
Kết bài
Nếu trước đây Patroni với bạn chỉ là một cái tên thường xuất hiện trong các sơ đồ HA cho PostgreSQL, thì sau bài viết này hy vọng cách nó hoạt động đã trở nên rõ ràng và cụ thể hơn. Thay vì chỉ nhìn Patroni như một công cụ “tự động failover”, giờ bạn có thể hình dung rõ hơn cách nó theo dõi trạng thái cluster, bầu chọn leader mới khi có sự cố, và phối hợp với Kubernetes để tránh những tình huống nguy hiểm như split-brain. Khi đã hiểu được phần vận hành bên trong này, bạn sẽ tự tin hơn không chỉ khi bắt đầu triển khai Patroni mà còn khi đánh giá liệu nó có thực sự phù hợp với hệ thống Kubernetes của mình hay không.
Về bản chất, Patroni giải quyết bài toán high availability cho PostgreSQL bằng cách liên tục duy trì một leader lock trên DCS và tự động kích hoạt quá trình bầu chọn khi lock hết hạn. Các cơ chế cốt lõi phối hợp với nhau theo ba tầng:
- Vòng lặp health check giúp trạng thái cluster được kiểm tra liên tục. Primary thực hiện renew lock, trong khi các Replica theo dõi lock để phát hiện sớm khi có sự cố.
- Leader race xảy ra khi lock hết hạn. Các Replica sẽ cạnh tranh quyền trở thành Primary mới dựa trên các điều kiện như replication lag, WAL timeline và quorum; đồng thời Patroni sử dụng resourceVersion của Kubernetes để đảm bảo chỉ một node có thể giành lock, từ đó ngăn split-brain.
- Failsafe Mode đóng vai trò như lớp dự phòng khi DCS gặp sự cố. Trong trạng thái này, Primary vẫn có thể tiếp tục hoạt động nếu còn liên lạc được với toàn bộ cluster, nhưng đổi lại hệ thống sẽ không còn khả năng failover tự động.
Nhìn rộng hơn, Patroni phù hợp với những hệ thống cần mức độ kiểm soát cao và muốn tự vận hành PostgreSQL trên Kubernetes. Với các workload ưu tiên sự đơn giản trong vận hành, managed services vẫn là lựa chọn đáng cân nhắc hơn.