3177
1H200.141S.44V
H200 SXM5 141GB
109.981.800đ
/ 1 Tháng
- GPU1 GPU
- CPUAMD Genoa
- Core44 Core
- RAM240 GB RAM
- VRAM141GB VRAM
- NVLink/P2PP2P: No
- Disk6000GB
- Ghi chúVisible product • Single GPU AI compute


Triển khai GPU Cloud với NVIDIA H200 SXM5 141GB, AMD Genoa CPU, disk 6000GB và tùy chọn 1–8 GPU theo đúng nhóm sản phẩm 3177–3180.
NVIDIA DGX H200 được thiết kế cho các workload AI cần VRAM lớn, throughput ổn định và khả năng mở rộng đa GPU để huấn luyện, tinh chỉnh hoặc inference mô hình lớn.
Hạ tầng GPU H200 SXM5 141GB cho AI training, fine-tuning, inference và workload HPC cần VRAM lớn.
Cấu hình từ 1 GPU đến 8 GPU, VRAM mở rộng từ 141GB đến 2048GB theo từng gói sản phẩm.
CPU AMD Genoa nhiều core giúp tăng tốc pipeline dữ liệu, preprocessing và workload tính toán song song.
Tùy chọn P2P hoặc NVLink 900GB/s giúp tăng hiệu quả trao đổi dữ liệu giữa GPU trong workload đa GPU.
H200 SXM5 141GB
H200 SXM5 141GB
H200 SXM5 141GB
H200 SXM5 141GB
Cấu hình H200 giúp mở rộng năng lực GPU cho nhiều giai đoạn: thử nghiệm, fine-tuning, training và production inference.
H200 SXM5 141GB phù hợp mô hình LLM, multimodal AI, computer vision và inference batch lớn.
Chọn 1, 2, 4 hoặc 8 GPU để cân bằng chi phí, hiệu năng và nhu cầu scale của dự án.
Tất cả cấu hình H200 được cung cấp disk 6000GB cho dataset, model checkpoint và artifact.
Hỗ trợ 1, 3, 6, 12, 24, 36, 48 và 60 tháng theo dữ liệu sản phẩm.
HiTechCloud hỗ trợ tư vấn driver, CUDA, runtime, framework và cấu hình triển khai GPU cloud.
Phù hợp triển khai training, fine-tuning, RAG, embedding, inference và nền tảng AI doanh nghiệp.
Dùng DGX H200 cho fine-tuning, instruction tuning, model evaluation và pipeline GenAI doanh nghiệp.
Phục vụ mô hình AI với VRAM 141GB/GPU, phù hợp batch inference và workload cần bộ nhớ lớn.
Tăng tốc mô phỏng, phân tích dữ liệu, rendering, nghiên cứu khoa học và workload GPU chuyên sâu.
Năng lực mạnh mẽ, được tối ưu để tăng tốc AI/ML và các workload hiệu năng cao ở mọi quy mô.
Huấn luyện, inference hay fine-tuning — HiTechCloud luôn có đúng GPU bạn cần, với mức giá minh bạch và môi trường triển khai theo yêu cầu.
HiTechCloud GPU instance kết hợp NVLink/PCIe, InfiniBand (RDMA) và RAIL topology để tối ưu hiệu năng AI/HPC.
Thiết kế mạng và GPU fabric giúp workload AI mở rộng ổn định, giảm nghẽn băng thông và duy trì hiệu năng khi chạy ở quy mô lớn.

Kết nối GPU-to-GPU tốc độ cao trong và giữa các node, xóa bỏ điểm nghẽn khi huấn luyện mô hình.

Kết nối độ trễ thấp, tối ưu cho huấn luyện phân tán và giảm thiểu tải xử lý trên máy chủ.
Kiến trúc mạng song song mang đến băng thông cao hơn, khả năng dự phòng và hiệu năng ổn định ở mọi quy mô.
Từ một GPU đến quy mô lớn, HiTechCloud chủ động chuẩn bị tài nguyên trước và tận dụng tối đa hiệu năng của từng instance.
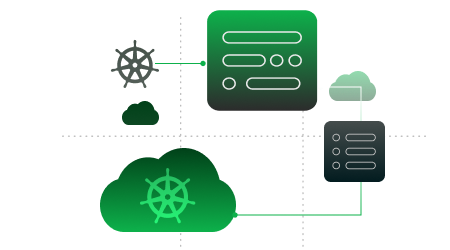
Tự động điều chỉnh tài nguyên GPU từ quy mô nhỏ đến hàng nghìn GPU, với khả năng dự báo và cấp phát tài nguyên trước khi bạn cần.

Hỗ trợ truy cập qua SSH, TCP và HTTP với các lớp bảo vệ tích hợp sẵn, bảo toàn dữ liệu doanh nghiệp và kiểm soát toàn bộ quyền truy cập.
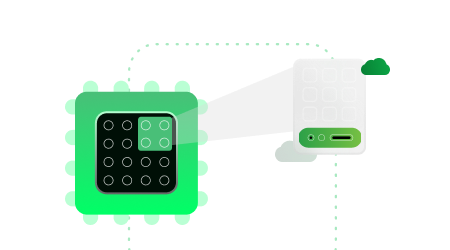
Phân chia một GPU thành nhiều instance độc lập để chạy song song nhiều AI workload, tối ưu tài nguyên và giảm chi phí hạ tầng.
Từ huấn luyện quy mô lớn đến inference thời gian thực — chỉ trả tiền khi bạn thực sự chạy, với nền tảng GPU Cloud được xây dựng để phục vụ mọi workload AI và hiệu năng cao.
Từ đăng ký đến khởi chạy GPU instance trong chưa đầy 5 phút — không cài đặt phức tạp, không đặt trước tài nguyên, không tốn phí khi nhàn rỗi. Chỉ cần triển khai, chạy và trả tiền đúng những gì bạn dùng.
Nền tảng quản lí toàn diện giúp triển khai và vận hành AI agent an toàn ở quy mô lớn với hạ tầng chuẩn doanh nghiệp.
Khám phá AgentBaseNền tảng thống nhất để huấn luyện, fine-tuning và triển khai mô hình AI ở mọi quy mô.
Khám phá AI PlatformHỗ trợ tìm kiếm nhanh, phân tích thời gian thực, dữ liệu log, sự kiện quy mô lớn và vector database cho RAG.
Khám phá Vector DatabaseDịch vụ Kubernetes được quản lý cho việc điều phối container, AI service và workload GPU cloud.
Khám phá KubernetesTriển khai hệ thống và ứng dụng đến gần khách hàng hơn, giảm độ trễ và đáp ứng yêu cầu tuân thủ quy định địa phương.
BKK-01
HCM-01 · HCM-02 · HCM-03
HAN-01 · HAN-02

Các doanh nghiệp hàng đầu và startup tăng trưởng nhanh tin chọn HiTechCloud nhờ các giải pháp AI Cloud bảo mật, hiệu năng cao, giúp đổi mới và mở rộng quy mô.
Đội ngũ HiTechCloud tư vấn kiến trúc GPU, network, bảo mật và phương án vận hành phù hợp với workload thực tế.
Thông tin nhanh trước khi chọn NVIDIA DGX H200 tại HiTechCloud.
Phù hợp AI training, fine-tuning, inference, HPC, simulation, data science và workload cần VRAM lớn.
Tất cả gói trong dữ liệu được cấu hình disk 6000GB.
DGX H200 phù hợp hơn cho workload cần dung lượng bộ nhớ GPU lớn, dataset nặng và mô hình AI có yêu cầu VRAM cao.
Có. DGX H200 phù hợp inference LLM, fine-tuning, model serving, RAG pipeline và các tác vụ AI cần bộ nhớ lớn.
Có. HiTechCloud hỗ trợ tư vấn số GPU, CPU, RAM, storage, runtime và framework theo quy mô workload.
Nên chọn khi mô hình, batch size hoặc dataset vượt giới hạn GPU phổ thông và cần nền tảng data center ổn định.
Các gói hỗ trợ 1, 3, 6, 12, 24, 36, 48 và 60 tháng.
HiTechCloud hỗ trợ chọn số GPU, VRAM, CPU core, storage, runtime và phương án vận hành GPU cloud phù hợp.




































































Bắt đầu triển khai nhanh chóng với HiTechCloud
Thông báo mới, phân tích chuyên sâu và sự kiện


































Khởi tạo giải pháp và kết nối với HiTechCloud để định hình chiến lược AI & Cloud toàn diện
Đăng nhập để khám phá hệ sinh thái hơn 30 sản phẩm cùng những tiện ích dành cho bạn
Bắt đầu
Kết nối với đội ngũ kinh doanh và khám phá giải pháp AI & Cloud tối ưu cho doanh nghiệp của bạn
Liên hệ SalesCông ty Cổ Phần Giải Pháp Công Nghệ và Phần Mềm Phổ Tuệ
Địa chỉ: 128 Đường Bình Mỹ, xã Bình Mỹ, Thành phố Hồ Chí Minh, Việt Nam
Mã số thuế: 0318222903 do Sở KH & ĐT TPHCM cấp lần đầu ngày 20/12/2023, chỉnh sửa lần thứ 2 ngày 15/10/2024
Chịu trách nhiệm nội dung: Nguyễn Thanh An
Hotline: Số điện thoại: 0865.920.041
Email: Email: info@photuesoftware.com
Email Abuse: abuse@photuesoftware.com
Giấy chứng nhận: Đăng ký cung cấp dịch vụ viễn thông số 18/GCN-SKHCN, do Sở Khoa học và Công nghệ Thành phố Hồ Chí Minh cấp ngày 10/03/2026.
Căn hộ OT03, Tòa nhà The Landmark 81, 720A Đ. Điện Biên Phủ, Vinhomes Tân Cảng, Phường Thạnh Mỹ Tây, Tp. Hồ Chí Minh
5F, Ginza Sky Building, 3-13-4 Ginza, Chuo-ku, Tokyo, Japan
Email: contact.jp@hitechcloud.asia
6F, Yanghwa Tower, 5 Teheran-ro 20-gil, Yeoksam-dong, Gangnam District, Seoul, South Korea
5F, Sugimoto Building, 1-4-7 Tokui-cho, Chuo-ku, Osaka, Japan
Email: contact.jp@hitechcloud.asia
7F, ONE FUKUOKA BLDG, 1-11-1 Tenjin, Chuo-ku, Fukuoka, Japan
Email: contact.jp@hitechcloud.asia
81-83 Campbell Street Surry Hills, NSW 2010, Australia
Email: sydney@hitechcloud.asia
150 E Brokaw Rd, San Jose, CA 95112, United States
Email: contact.us@hitechcloud.asia
36 Robinson Road, #20-01, City House, Singapore 068877
Email: contact.sgp@hitechcloud.asia
Mezzanine Floor, Jumeirah Living Marina Gate 3, Dubai Marina, Dubai, PO Box 121828



